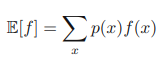베타 분포 베타 분포 베르누이 분포, 이항 분포 이산 확률 변수 - 베르누이 분포, 이항 분포 베르누이 분포 동전 던지기 이진 확률 변수 x ∈ {0,1}을 고려해 보자. x=0은 뒷면, x=1은 앞면이다. 동전이 망가져서 앞면, 뒷 mldiary.tistory.com 이항 분포에서 사전 분포를 도입하기 위해 켤레성을 가지게 하는 베타 분포에 대해 알아보았다. 여기서는 이항 분포가 아닌 다항 분포에서 사전 분포를 도입하기 위해 켤레성을 가지게 하는 디리클레 분포에 대해 알아보자. (사전 분포를 도입하는 이유는 위의 글에서 설명했듯이 베이지안 접근법을 이용하여 불확실성을 표현하고자 하기 때문이다.) 다항 분포의 매개변수 {µk}에 대해 살펴보자. 다항 분포의 형태를 살펴보면 켤레성을 띄기 위해 사전 분포가..