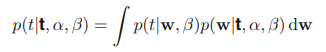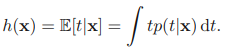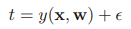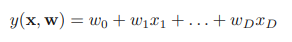이전 글에서 직선 피팅 예시를 통해 베이지안 선형 회귀의 학습 방법을 알아 보았다. 베이지안 선형 회귀 - 직선 피팅 예시 (tistory.com) 베이지안 선형 회귀 - 직선 피팅 예시 선형 회귀 파라미터 최적화 - 최대 가능도 (tistory.com) 선형 회귀 파라미터 최적화 - 최대 가능도 선형 회귀의 파라미터 w를 최적화하기 위해 최대 가능도 방법을 이용해보자. 최대가능도를 이용한 mldiary.tistory.com 여기서는 w의 값을 알아내기 위해 학습을 반복했는데 실제 상황에서는 결국 새로운 x값에 대해 t의 값을 예측하는 것이 목표이다. 이를 위해서는 다음과 같이 정의되는 예측 분포(predictive distribution)를 고려해야 한다. t는 훈련 데이터로으로 이루어진 벡터이다. 이..