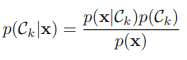가장 단순한 형태의 선형 회귀 모델은 입력 변수들의 선형 결합을 바탕으로 한 모델이다. 이를 선형 회귀(linear regression) 모델이라고 부른다. 선형 회귀의 가장 중요한 성질은 매개변수 w0, ... , wD의 선형 함수라는 것이다. 또한 이 모델은 입력 변수 xi의 선형 함수이기도 한데, 바로 이 성질 때문에 선형 회귀 모델에는 심각한 한계점이 존재한다. 이러한 한계점을 극복하기 위해 다음처럼 입력 변수에 대한 고정 비선형 함수들의 선형 결합을 사용할 수 있다. 여기서 φj (x)가 기저 함수(basis function)이다. 이 모델의 배개변수의 총 숫자는 M-1 + 1(w0) = M이 된다. 매개변수 w0은 데이터에 있는 편향을 표현할 수 있게 해준다. 따라서 편향 매개변수라고 부르기도..