결정 이론(decision theory)란 불확실성이 존재하는 상황에서 최적의 의사결정을 내리는 방법에 대한 이론이다. 특히 분류 문제에서 여러가지 label값들 중 하나의 값의 확률이 100%로 나타나는 것이 아니라면 예측 결과가 틀릴 수도 있는 위험에 처하게 된다. 이러한 불확실성이 존재하는 상황에서 결정을 내리는 3가지 방법론에 대해 소개한다.
결정 이론을 이해하고 비교하기 위해 다음과 같은 예시를 생각해보자. 환자의 엑스레이 이미지를 바탕으로 그 환자가 암에 걸렸는지 아닌지 판단하는 진단 문제를 고려해보자. 이 경우 입력 벡터 x는 이미지의 픽셀 강도 집합에 해당할 것이며, t는 환자가 암에 걸렸는지 아닌지를 나타내는 출력 변수일 것이다. 여기서는 환자에게 암이 있다고 판단할 경우에는 클래스 C1으로, 그렇지 않을 경우에는 C2로 표현하도록 하자.
우리는 이미지가 주어졌을 때 각각의 클래스의 조건부 확률을 알고싶으며 이는 p(Ck|x)로 표현된다. 베이지안 정리를 사용하면 다음과 같은 형태로 표현할 수 있다.

오분류 비율의 최소화
우리 목표가 단순히 잘못된 분류 결과의 숫자를 가능한 한 줄이는 것이라고 해보자. 이를 위해 각각의 입력 변수 x를 가능한 클래스 중 하나에 포함시켜야 한다. 따라서 입력 공간을 결정 구역(decision region)이라고 볼리는 구역 Rk들로 나누게 될 것이다. Rk는 클래스 수만큼 존재하고, Rk에 존재하는 모든 포인트들은 클래스 Ck에 포함될 것이다. 이러한 결정 구역들 사이의 경계를 결정 경계(decision boundary)혹은 결정 표면(decision surface)라고 부른다.
우리의 목적은 오분류의 비율을 최대한 낮추는 것이다. 따라서 잘못 분류할 확률 즉 실수할 확률을 p(mistake)라고 나타내면 실수가 발생할 확률은 다음과 같이 주어진다.

예시로 든 암 진단 문제의 경우 클래스가 두 개 존재한다. 따라서 다음과 같이 두 개의 항으로 표현된다. 위의 식을 쉽게 해석해보자. 첫 번째 항은 C2의 클래스를 가지고 있는 데이터가 결정 구역 R1에 포함될 확률을 나타낸다. 즉, 환자에게 암이 실제로는 없는데(C2) 암이 있다고(R1) 판별할 확률이다. 두 번째 항은 반대로 환자에게 암이 실제로 있는데(C1) 없다고 판별할(R2)확률이다.
여기서 결합확률 p(x, Ck)는 확률의 곱의 법칙에 따라 p(Ck|x)p(x)로 표현될 수 있고 p(x)는 모든 항에서 같은 값을 가진다. 따라서 p(mistake)를 최소화하기 위해서는 각각의 x를 사후 확률 p(Ck|x)가 최대가 되는 Rk에 포함시키면 된다. 그래야 오차로 판명되는 Rk'로 적분한 값이 최소가 되기 때문이다.
더 일반적으로 K개 클래스를 가진 경우 올바르게 분류된 경우의 확률을 극대화 하는 편이 조금 더 쉽다.

여기서도 마찬가지로 각각의 x를 사후 확률 p(Ck|x)가 최대가 되는 Rk에 포함시키면 p(correct)가 최대화 된다.
아래 그림을 통해 오분류 비율의 최소화 결정 이론을 직관적으로 받아들일 수 있다.
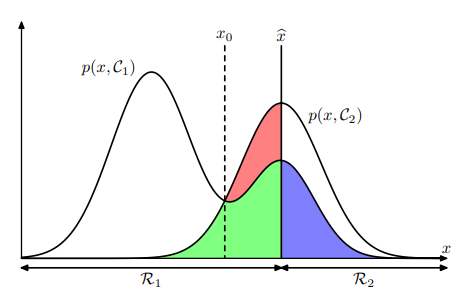
위의 그림에서 x^를 결정 경계로 생각해보자. 그러면 C1을 고려할 때 오분류할 확률은 C1인데 R2로 분류할 확률인 파란색 영역에 해당한다. 그리고 C2를 고려해보면 C2인데 R1으로 분류할 확률은 녹색 영역 + 붉은색 영역에 해당한다. 즉 전체 영역 중 색칠된 영역의 비율이 p(mistake)로 나타나게 되는데 이를 최소화하기 위해서는 p(Ck|x)가 최대가 되는 클래스에 포함시키면 된다는 것을 알 수 있다.
기대 손실의 최소화
첫 번째 이론은 그저 오분류의 비율을 최소화 시키는 것에만 관심이 있었다. 하지만 많은 적용 사례에서의 목표는 단순히 오분류의 숫자를 줄이는 것보다 훨씬 더 복잡할 수 있다. 의학적 진단 문제를 다시 고려해 보자. 만약 암에 걸리지 않은 환자(C2)를 걸렸다고 판단(R1)하면 이는 별로 심각한 문제가 아니다. 그냥 정밀 검사를 한 번 더 받아보면 되기 때문이다. 그러나 암에 걸린 환자가(C1)암에 걸리지 않았다고 판단(R2)하면 문제는 심각하다. 적절한 치료를 받지 못해 치명적일 수 있기 때문이다. 따라서 이러한 경우 전체 실수의 확률이 늘어나는 한이 있더라도 두 번째 종류의 실수를 줄이는 것이 중요하다는 것을 알 수 있다.
비용 함수(cost function)라고도 불리는 손실 함수(loss function)을 도입함으로써 이러한 문제를 공식화할 수 있다.

실제 클래스가 Ck인 입력값 x를 Cj(j=k일수도, k와 다를수도 있다)로 분류했다고 가정하자. 이 과정에서 우리는 Lkj로 표현할 수 있는 손실을 발생시키게 된다. Lkj는 손실 행렬의 k, j번째 원소로 볼 수 있다. 현재 문제에서 손실 행렬은 위에 나타나있다. 행 방향은 실제 x의 클래스, 열 방향은 우리 모델이 분류한 클래스이다. 암을 암으로 판단한 것(L11)과 정상을 정상으로 판단한 것(L22)는 0의 값 즉, 손실값을 발생시키지 않는다. 정상을 암으로 판별한 경우(L21)손실값이 발생하지만 1로 매우 작은 값을 가진다. 그리고 만약 암을 정상으로 판별했을 경우(L12) 손실값은 1000으로 L21보다 1000배 더 큰 손실을 발생시킨다. 이런 성질을 띄는 손실 함수를 확률 모델에 추가하면 다음과 같다.

확률의 곱의 법칙을 이용하여 위의 식을 해석하면 결국 다음 식을 최소화하는 클래스 j에 할당하는 것이 E[L](손실 기댓값)을 최소화하는 것이라는 걸 알 수 있다.

따라서 각각의 클래스의 사후 확률 p(Ck|x)를 알고 나면 이 방법을 쉽게 실행할 수 있다.
거부 옵션
입력 공간 중 어떤 구역에서는 사후 확률 p(Ck|x)중 가장 큰 것이 1보다 매우 작다. 즉 결합 확률 p(x,Ck)들이 비슷한 값을 가지고 있다는 것이다. 이 구역들에 대해서는 해당 구역이 어떤 클래스에 속할지 확신 정도가 적은 것이다. 몇몇 적용 사례에서는 오류 비율의 최소화를 위해 이렇게 확실하지 않은 구역에 대해서 결정을 피하기도 한다. 이것을 거부 옵션(reject option)이라고 부른다. 암 진단 예시에서 판단이 어려운 구역 즉, 확률 값이 각각의 클래스가 비슷한 입력값 x들을 사람이 직접 보고 판단할 수 있도록 모델이 직접 결정을 내리지 않고 보류하는 것이다.
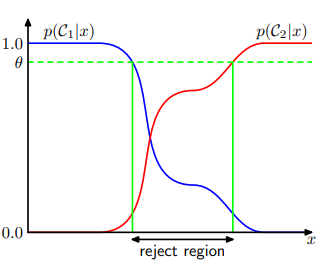
위의 그래프를보면 reject region이라고 나타나 있는 부분에 입력값 x가 들어오면 결정을 하지 않고 보류한다. 구역의 결정은 θ를 통해 일어난다. 최대의 확률을 나타내는 클래스가 θ를 넘기지 못할 경우 reject region으로 설정하는 것이다.
'Machine Learning > Classification' 카테고리의 다른 글
| 추론과 결정 (0) | 2023.01.28 |
|---|---|
| 스태킹 앙상블 (Stacking Ensemble) (0) | 2022.08.05 |
| 부스팅(Boosting) - XGBoost, LightGBM (0) | 2022.08.04 |
| 배깅(Bagging) - 랜덤 포레스트(Random Forest) (2) | 2022.08.02 |
| Ensemble Learning - Voting(보팅) (1) | 2022.08.02 |