이번 글에서는 부스팅(Boosting)과 대표적인 부스팅 알고리즘인 XGBoost, LightGBM에 대해 소개한다.
Boosting
부스팅은 여러 개의 약한 학습기(weak learner)를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가며 학습하는 방식이다.
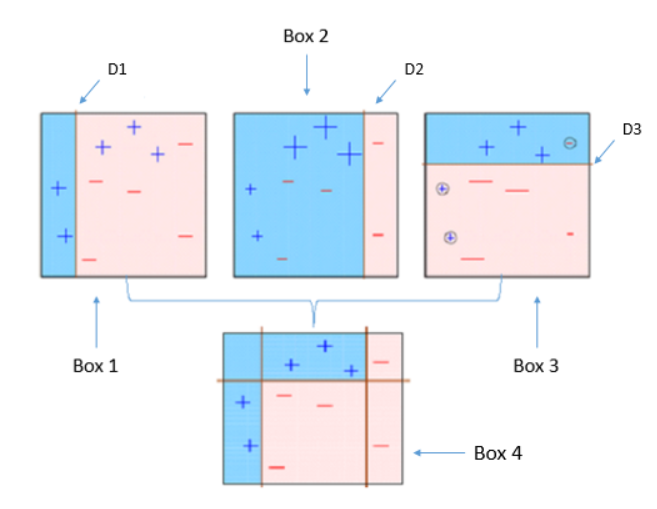
위의 그림은 부스팅의 기본 알고리즘을 그림으로 나타낸 것이다. 부스팅은 다음과 같은 순서로 진행된다.
- 첫 번째 분류기 이용하여 데이터셋을 분리한다(Box 1). 세 개의 Positive 데이터가 잘못 분류된 것을 확인할 수 있다.
- Box 1에서 잘못 분류된 데이터에 가중치를 두어 옳게 분류할 수 있도록 두 번째 분류기를 생성한다. 그 결과 Negative 데이터 3개가 잘못 분류된 것을 확인할 수 있다.
- 설정한 분류기의 개수만큼 2의 과정을 반복한다.
- 생성된 분류기들에 각각 가중치를 부여하여 결합한다(모든 분류기를 동일하게 반영하지 않고 나중에 만들어진 분류기일 수록 높은 가중치를 두고 반영한다).
다음은 부스팅에서 공통적으로 사용되는 하이퍼 파라미터이다.
- learning_rate: 학습률이라고도 하며 오류값을 보정할 때 사용되는 계수로 너무 높으면 최소 오류를 지나칠 수 있고 너무 낮으면 local optima에 빠져 최소 오류를 찾지 못하거나 도달하는데 많은 시간이 걸릴 수 있다.
- n_estimators: 분류기(weak learner)의 개수를 의미한다 많을수록 성능이 좋지만 과적합이 발생하거나 시간이 너무 오래 소요될 수 있다.
- subsample: 하나의 분류기가 학습에 사용하는 데이터 샘플링 비율이다. 기본값은1이며 전체 데이터를 이용한다는 의미이다.
XGBoost Vs. LightGBM
XGBoost는 부스팅 계열 알고리즘 중 가장 성능이 좋은 알고리즘 중 하나이다. XGBoost의 특징은 다음과 같다.
- 오류 보정에 경사 하강법(Gradient Descent)이 이용되는 GBM(Gradient Boosting: 부스팅 중에서도 경사 하강법을 이용하는 알고리즘) 계열의 부스팅이다.
- 병렬 CPU환경에서 병렬 학습이 가능해 기존 GBM보다 빠른 학습이 가능하다.
- 자체적으로 과적합 규제 기능이 있어 과적합에 강한 내구성을 가진다.
LightGBM도 부스팅 계열 알고리즘 중 가장 성능이 좋은 알고리즘 중 하나이며 특징은 다음과 같다.
- 오류 보정에 경사 하강법(Gradient Descent)이 이용되는 GBM 계열의 부스팅이다.
- XGBoost에 비해 속도가 훨씬 빠르고 성능은 비슷하다.
- 데이터셋이 적을 경우 XGBoost보다 과적합에 취약할 수 있다.
- 다른 GBM이 균형 트리 분할 방식을 사용하는 것에 비해 LightGBM은 리프 중심 트리 분할 방식을 사용한다.
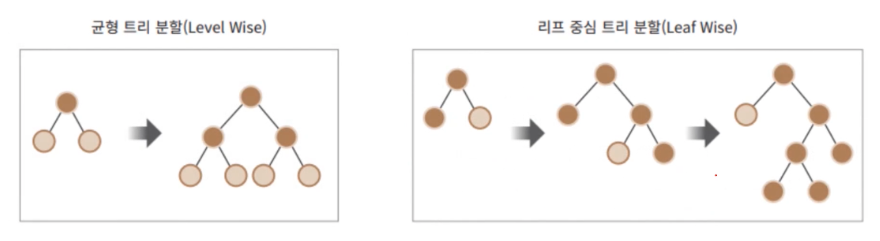
균형 트리 분할은 트리의 깊이를 최대한 줄이기 위해 각 노드의 깊이가 비슷하도록 균형적으로 생성하는 알고리즘이다. 리프 중심 트리 분할은 트리의 균형을 맞추지 않고 최대 손실값을 가지는 리프 노드를 지속적으로 분할하며 비대칭적인 규칙 트리를 생성한다. 대부분의 GBM은 균형 트리 분할 알고리즘을 이용하여 트리를 분할하지만 LightGBM은 리프 중심 트리 분할을 이용한다.
XGBoost와 LightGBM은 모두 자체적인 라이브러리로 제작되어, 같은 역할을 하는 하이퍼 파라미터나 메서드들이 다른 이름으로 구현되어 있다. 이러한 문제를 해결하기 위해 두 알고리즘 모두 사이킷런(sk-learn)라이브러리와 이름이 동일하도록 사이킷런 래퍼가 구현되어 있다. 후자를 사용하는 쪽이 구현에 있어 훨씬 편리하다.
다음은 XGBoost와 LightGBM이 모두 가지고 있는 중요 하이퍼 파라미터이다.
- early_stopping_rounds: n_estimators로 생성할 분류기의 개수 1000으로 설정하였다고 하자. 그런데 이미 500번째 트리를 생성할 때 최적으로 적합되어 나머지 500개를 생성하는 동안 loss값이 줄어들지 않는다면 더이상 학습을 진행하는 것이 의미가 없을 것이다. 따라서 early_stopping_rounds값을 설정하면 해당 값만큼 분류기가 생성되면서 loss값이 개선되지 않으면 학습을 종료한다(예: early_stopping_rounds가 50일 경우 마지막으로 loss값이 개선된 이후로 50번 동안 loss가 개선되지 않으면 학습을 강제 종료한다).
'Machine Learning > Classification' 카테고리의 다른 글
| 세 가지 결정 이론(오분류 비율 최소화, 기대 손실 최소화, 거부 옵션) (0) | 2023.01.27 |
|---|---|
| 스태킹 앙상블 (Stacking Ensemble) (0) | 2022.08.05 |
| 배깅(Bagging) - 랜덤 포레스트(Random Forest) (2) | 2022.08.02 |
| Ensemble Learning - Voting(보팅) (1) | 2022.08.02 |
| 결정 트리(Decision Tree) (0) | 2022.05.27 |