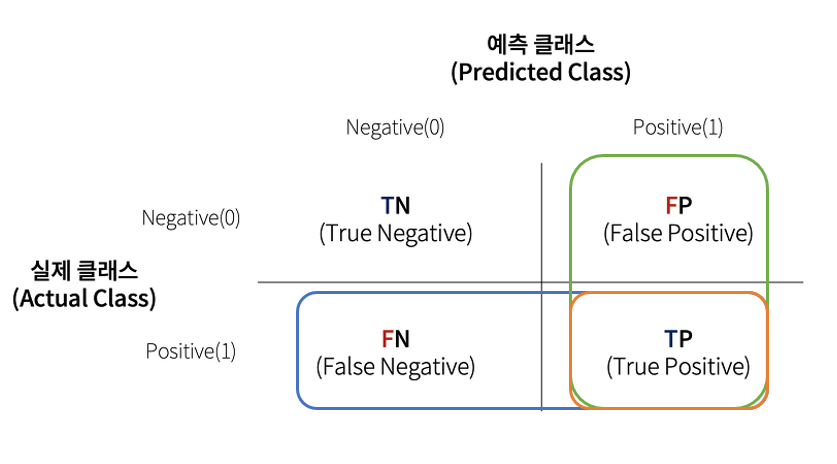
이번 글에서는 kaggle에서 제공하는 피마 인디언 당뇨병 데이터셋을 이용하여 당뇨병 여부를 판단하는 예측 모델 수립, 여러가지 성능 지표를 이용하여 모델의 성능을 평가한다. 피마 인디언 당뇨병 데이터 세트는 다음 피처로 구성된다.Pregnancies: 임신 횟수Glucose: 포도당 부하 검사 수치BloodPressure: 혈압SkinThickness: 팔 삼두근 뒤쪽 피하지방 측정값Insulin: 혈청 인슐린BMI: 체질량지수DiabetesPedigreeFunction: 당뇨 내력 가중치 값Age: 나이Outcome: 클래스 결정 값(0또는 1)먼저 모델 구현 및 성능 평가를 위한 라이브러리를 import하고, 데이터를 불러와 확인한다. 레이블이 불균등하게 분포하므로 Stratify를 이용하여 학습셋..