1) Data 준비
서울대학교 임상약리학과에서 제공받은 HPLC-MS/MS 데이터셋으로 진행하였다. 이 데이터셋은 정상인 66명, 신장질환을 가진 환자 220명의 대사체 분석 결과이다.
2) 알고리즘 설계

신장 질환 데이터는 ‘group’ column에 발병 원인이 나타나 있고 일반인인 경우 normal로 표시되어 있다. 따라서 해당 column이 레이블이 된다. Sample은 ID와 같은 학습에 필요 없는 일련번호이므로 삭제하였다. 그 이후로 나오는 모든 column은 대사체의 발현량 데이터이다.
첫 번째 실험으로 발병 원인에 따라 다른 레이블을 부여하여, 발병 원인까지 예측할 수 있는 모델을 설계해 보았다.
오버 샘플링 등의 전처리 후 랜덤 포레스트 모델을 이용하여 정확도를 예측해 보았다. 결정 트리의 개수는 1000개, 최대 깊이는 100으로 정의하였다. 그 결과 정확도는 0.58이 산출되었다. 멀티 클래스 분류이기 때문에 이진 분류보다 정확도가 낮아질 수 있다는 점을 감안하여도 거의 분류를 하지 못하는 모습을 보였다. 이렇게 낮은 정확도를 보이는 이유는 발병 원인이 다르더라도 결국 같은 신장 질환을 일으켰기 때문에 대사체의 농도는 비슷한 양상을 띌 확률이 높다. 따라서 대사체의 농도를 기준으로 여러 원인들을 분류하는 모델이 낮은 정확도를 나타낸 것이다.
다음 그래프는 가장 feature importance간 높은 F0360 대사체의 농도를 레이블에 따라 나누어 히스토그램을 그린 결과이다. 1행1열의 그래프는 전체 데이터, 1행 2열, 2행 1열, 2행 2열, 3행 1열은 각각의 원인에 따른 F0360 대사체의 데이터, 마지막은 일반인의 데이터이다. 데이터의 경향성을 살펴보면 물론 근소한 차이는 있지만 4개의 원인에 따른 그래프는 크게 다른 양상을 나타내지 않지만, 일반인 데이터와는 차이를 보이는 것을 확인할 수 있다. 따라서 다음으로는 멀티 클래스 분류가 아닌 일반인과 환자만을 나누는 이진 분류기를 설계하여 보았다.
레이블 인코딩을 모든 원인을 1로 설정하여 두 개의 레이블을 가지는 이진 분류 데이터를 생성하였다.
전처리 이후 랜덤 포레스트 모델을 생성하여 성능 지표를 확인하였다. 정확도 93.1%로 이전 멀티클래스 분류에 비해 훨씬 높은 값을 가졌다.
Feature importance 분석 결과 F0426, F0360이 가장 중요한 피처로 나타났다. 이 중 F0360을 이용해 히스토그램을 그려 시각화 하였다.
왼쪽이 일반인, 오른쪽이 환자 데이터이다. 일반인 데이터는 평균 1.3의 정규분포를 띄는 그래프이고, 환자 데이터는 평균 1.2의 정규분포를 띄는 그래프이다. 이전 대장암 대장세포 데이터에 비해서는 겹치는 부분이 많지만 확실히 두 그래프가 다른 경향성을 나타내고 있다. 환자의 경우 F0360 대사체가 높은 농도를 나타내는 것을 확인할 수 있었다.
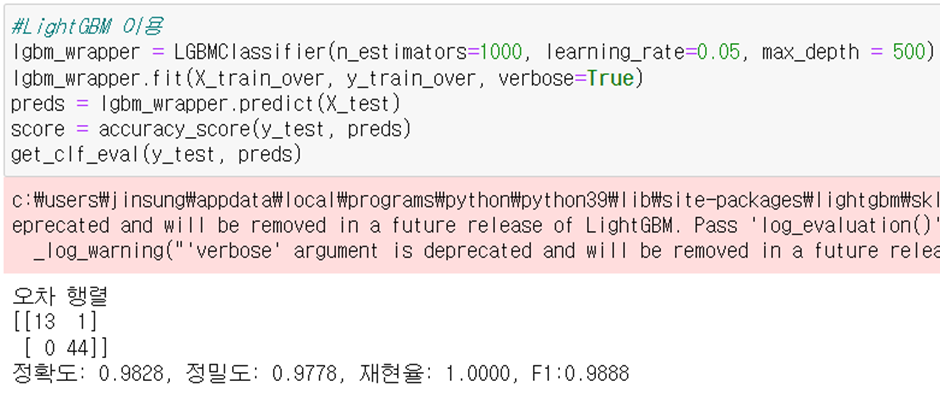
다음으로는 LightGBM이라는 성능이 더 좋은 모델을 이용하여 분류기를 생성하였다. 결정 트리의 개수는 1000, 학습률 0.05, 최대 깊이 500으로 설정하였다. 결과는 정확도 0.9828로 랜덤 포레스트 모델보다 훨씬 높은 정확도를 기록하였다. 오차행렬을 살펴보면, 맞추지 못한 데이터는 1개로 나타났다.
3) 대사체학에서 사용하는 방법론과의 비교
대사체학에서는 주로 ANOVA를 이용하여 집단간 비교에 있어 중요한 대사체들을 선정한다. 이는 이번 보고서에서 사용한 인공지능과는 다른 방법이다. 따라서 기존 대사체학에서 주로 사용하는 ANOVA와, 직접 제작한 인공지능 알고리즘 간 비교를 진행하였다.
| chi.squared | p.value | |
| F0360 | 129.57 | 4.80E-27 |
| F1515 | 116.15 | 3.55E-24 |
| F1661 | 115.44 | 5.02E-24 |
| F0795 | 105.07 | 8.17E-22 |
| F1374 | 102.17 | 3.39E-21 |
| F0426 | 102.17 | 3.39E-21 |
| F1362 | 100.53 | 7.60E-21 |
| F1468 | 97.367 | 3.57E-20 |
| F1365 | 95.601 | 8.49E-20 |
| F1654 | 92.65 | 3.60E-19 |
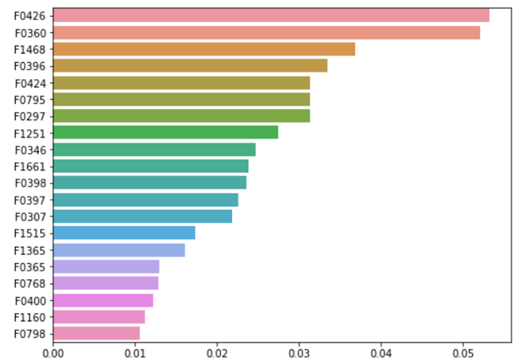
위쪽 표가 기존 방법론인 ANOVA를 통해 선정한 중요 feature이고, 아래쪽 그림이 직접 제작한 알고리즘을 통해 선정한 중요 feature이다. 두 결과 모두 중요도를 기준으로 내림차순으로 정리하였다. 각 결과에서 공통적으로 발견할 수 있는 중요 feature는 총 7가지이다. 표로 제시한ANOVA 분석 결과는 중요도 높은 feature 10가지를 선정한 것이다. 이 10가지 대사체 중에서 7가지 대사체가 공통적으로 확인되었으므로, 이는 직접 설계한 알고리즘이 기존에 사용되는 통계학적 분석법을 대체할 수 있는 정도의 정확도를 보이는 것으로 해석할 수 있다.
'Project > 드림학기제_Machine Learning 암 발병률 예측' 카테고리의 다른 글
| 결론 (0) | 2022.07.11 |
|---|---|
| 대장암 혈액 진단 (0) | 2022.07.11 |
| 대장암 진단 모델 (0) | 2022.07.11 |
| 전립선암 진단 모델 (0) | 2022.07.11 |
| 프로젝트 개요 및 이론적 배경 (0) | 2022.07.11 |