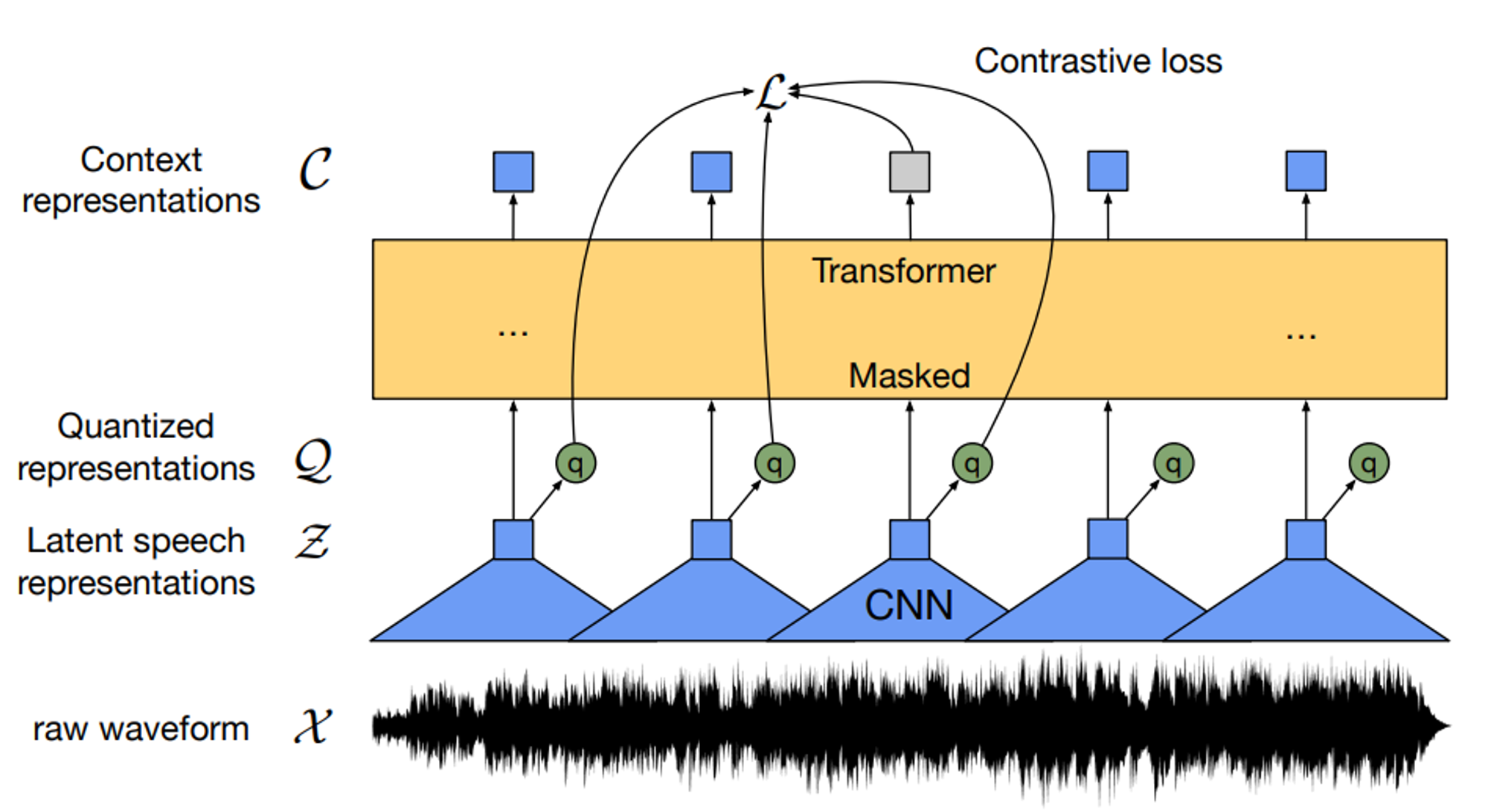
이 글에서는 2020 Neurips에 게재된 "wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations" (Alexei Baevski, et al)논문에 대해 리뷰한다. 제목 그대로 wav 음원을 vector (speech representation)으로 매핑하는 모델을 제안하였다. 이 논문을 TTS, STT에 넣은 이유는 wav2vec의 output에 간단한 predictor만 붙여주면 speech-to-text 모델로 사용할 수 있기 때문이다. ※ STT: Speech-To-Text, 음성을 텍스트로 변환해 주는 작업이다. Abstract이 연구에서는 처음으로 script없이 오디오로만 표현을 학습하고, script..