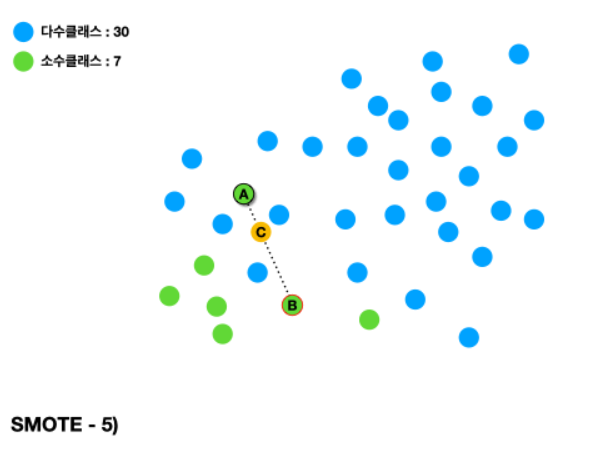
Over Sampling 분류 문제 중 간혹 클래스의 데이터 양이 균등하지 않은 경우가 있다. 예를들어 신용카드 기록 중 정상 기록과 신용카드 사기 기록을 분류한다고 할 때 모든 데이터셋에서 정상 기록이 월등히 많을 수 밖에 없다. 이렇게 불균등한 데이터셋으로 학습을 진행할 경우 모델이 bias를 가지게 되거나 데이터가 적은 클래스의 다양한 유형을 학습하지 못하는 문제가 있다. 이를 해결하기 위한 방법이 오버샘플링(Over Sampling)이다. 오버샘플링은 적은 데이터를 가진 클래스의 데이터를 다른 클래스와 동일한 크기로 증식시키는 방법이다. 언더 샘플링(under sampling, 오버샘플링과는 반대로 많은 데이터를 가진 클래스의 데이터를 적은 데이터를 가진 클래스와 동일한 크기로 감소시키는 방법)..