이 글에서는 2023 TASLP(Transactions on Audio, Speech and Language Processing)에 게재된 "Music Source Separation with Band-Split RNN" (Yi Luo, et al) 논문에 대해 리뷰한다.
Music source separation은 음악에서 여러 주요 악기들 (Vocal, Bass, Drum 등)을 분리하는 작업을 뜻한다. 이 논문은 band-split RNN을 이용하여 악기들을 효과적으로 분리하는 방법을 제시하였다.
Introduction
Problems
- 많은 MSS(Music Source Separation)모델들은 다른 research field에서 영감을 받은 이미 존재하는 architectures이다.
- research field EX) speech separation, image segmentation, human pose estimation, image recognition
- 이러한 다른 field에서 시작된 architectures가 왜 MSS에서 잘 동작하는지 설명할 수 없다.
- Labeled data가 부족하다.
- MSS에서 Labeled data는 각 악기를 따로 녹음한 것인데 이는 구하기가 어렵다.
Solutions
- 악기에 대한 사전 지식을 활용해서 band split하면 정확하지 않을까?

- Semi-supervised finetuning pipeline을 만들자.
- 적은양의 labeled data로 새로운 labeled data를 생성하여 semi-supervised 방식을 이용하자.
Band-Split RNN
Band-split RNN은 3가지 모듈로 이루어져 있다.
- Band split module: 인풋을 받아 band를 분할하는 모듈
- Band & sequence modeling module: 1.의 output을 받아 RNN을 통해 high-level feature extraction
- Mask estimation module: 2.의 output을 받아 feature로부터 음원을 다시 복원
1. Band split module
- Input: 음원의 spectrogram을 받음. F*T의 크기를 가짐 (F: frequency, T: time)
- frequency 대역을 k개의 subbands로 분할
- 잘게 분할되었을수록 feature extraction시 해당 대역폭을 더 자세히 볼 수 있음
- Normalization + Fully connected layer
- Output: N*K*T차원의 low-level feature 생성 (N: 각 subband를 N차원 feature로 변환, K: subbands의 개수, T: time)
2. Band & Sequence modeling module
- Input: Band split module의 output (N*K*T)
- sequence-level RNN 후 Band-level RNN
- 이 부분이 논문의 핵심이다. low-level의 feature를 가지고 RNN을 돌리는데 RNN은 해당 차원의 종속성을 고려할 수 있다. 즉 T차원으로 RNN을 돌리면 각 time간의 종속성을 모델링할 수 있고, K차원으로 RNN을 돌리면 각 subband간의 종속성을 feature에 모델링할 수 있다.
- 논문에서는(위의 그림 참조) T차원을 따라 Sequence-level RNN을 거친 후 바로 K차원을 따라 Band-level RNN을 거쳐 high-level feature를 출력한다.
- Output: N*K*T차원의 high-level feature 생성
3. Mask estimation module
- 이름이 mask estimation module이라서 WavLM처럼 특정 부분을 masking하고 예측하는건가? 생각할 수 있지만 그런게 아니라 전체 음원에서 어느 부분을 masking해야 우리가 원하는 악기만 남을 수 있을 지 예측하는 것이다.
- Input: N*K*T
- band-split module의 reverse 형태로 진행
- Normalizatoin + MLP
- Output: 주파수 영역이 masking된 F*T의 복원 spectrogram
Loss
MAE Loss를 사용해 학습을 진행한다.
Semi-Supervised Finetuning Pipeline
Motivation
Music source separation 학습을 진행하기 위해서는 음악 데이터와, label에 해당하는 각 악기를 따로 녹음한 음원이 필요하다. 하지만 이런 label이 있는 데이터는 구하기 어렵다. 그렇다고 적은 labeled data를 이용해서 학습하자니 모델 성능이 너무 떨어진다. 따라서 본 논문에서는 Semi-supervised finetuning pipeline을 제안한다.
Semi-supervised data sampling
위의 그림이 semi supervised pipeline이다.
- L(labeled data)를 이용해 기본 모델 P(pretrained classification model with labeled data)를 학습시킨다.
- U(unlabeled data)를 P에 넣고 separated target & residual을 분리한다.
(여기서 target은 분리하고자 하는 악기, redisual은 target을 제외한 배경음) - energy-based data filtering을 이용해 clean target/residual을 뽑아낸다.
(단순히 residual과 target의 dB차이가 30dB이상이면 clean한 dataset이라고 판별) - L 데이터와 filtering으로 뽑아낸 clean data를 sampling, mixing하여 새로운 데이터셋을 생성해낸다.
Result
Vocal separation
총 7가지의 hand-craft band split을 실험하였다. 각 버전이 어떻게 band를 분할하였는지는 위의 그림으로 확인할 수 있다. 각 버전의 성능은 다음과 같다.
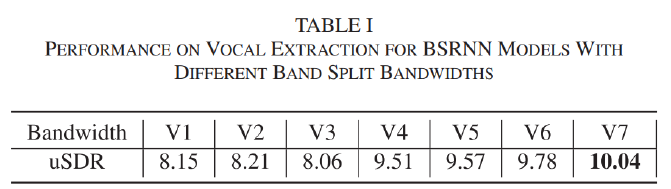
V7이 가장 성능이 높은 것을 알 수 있다. vocal extraction에서는 1kHz미만의 band를 자세히 보는 게 유리하다는 것을 알 수 있다.
Bass, Drum separation
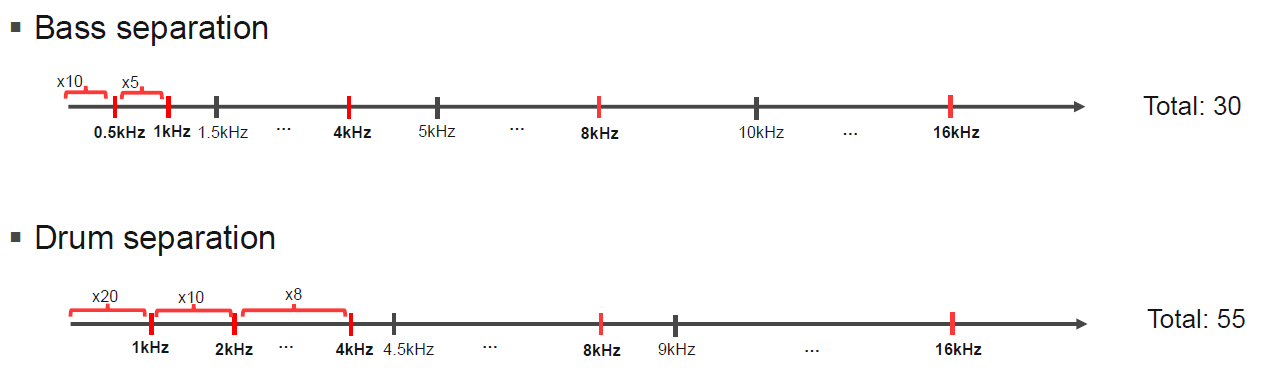
베이스와 드럼 모두 보컬보다 1kHZ미만을 세세하게 나눈 것을 볼 수 있다. Bass는 원래 음역대가 낮고, Drum은 kick과 같이 음역대 가낮은 부분이 있어 위와 같이 설정한 것으로 보인다.
Comparison
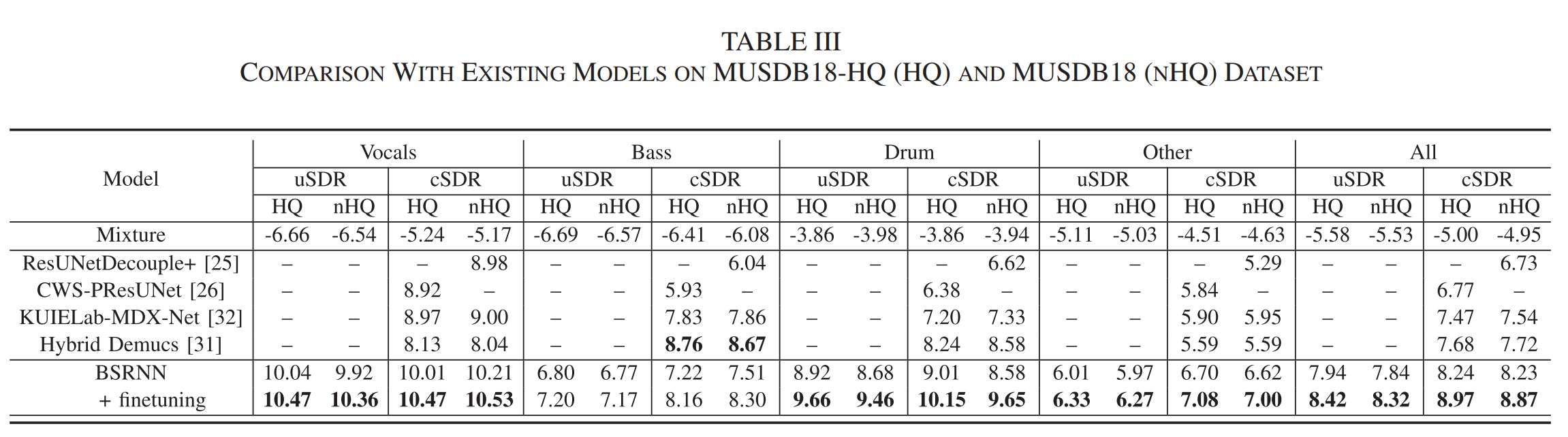
위의 표는 다른 MSS 모델들과 성능을 비교한 것이다. Bass를 제외하면 모든 악기에서 성능이 좋은 것을 확인할 수 있다. 이 결과에 대해서 논문에서는 Bass는 기본적으로 노래안에서 energy가 적어 Energy based data filtering이 적합하지 않았을 수도 있고, 아니면 band split이 적합하지 않았을 수도 있다고 얘기한다.
Discussion
읽다가 의문이 든 점은, Drum은 low-frequency, high-frequency에 골고루 분포하는데(high hat -> high, kick ->low) 보컬이나 베이스보다도 저주파에 집중적으로 band-split을 하였다.
내 생각은, high hat이나 snare는 소리가 크기때문에 분리가 쉽고, kick은 소리가 작기 때문에 저음역대를 세분화하는 방식으로 진행하였을 것 같다. 만약 그렇지 않다면, high-frequency는 잘 구별을 못해내는 단점이 있을 수 밖에 없을 것 같다.