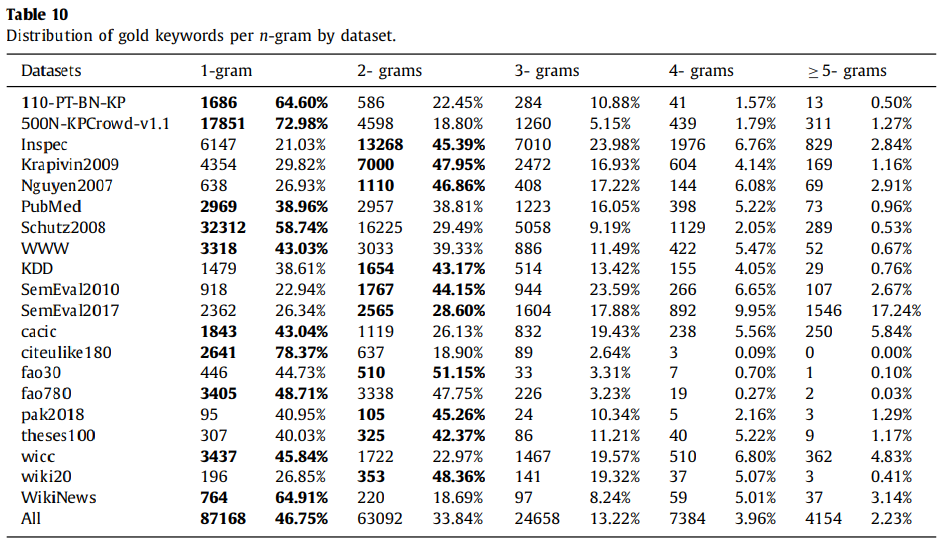
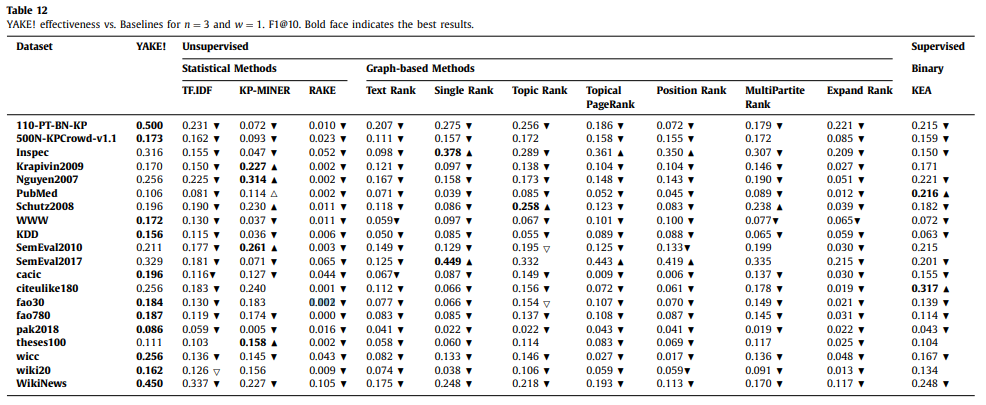
이번 글에서는 2020 Information Sciences에 게재된 "YAKE! Keyword extraction from single documents using multiple local features" (Ricardo Campos, et al) 논문을 리뷰한다.
YAKE!의 특징은 statistic feature를 활용한 unsupervised keword extraction이라는 점이다.
Introduction
YAKE는 단일 문서에서 추출된 통계적 텍스트 특징을 기반으로 가장 관련성 높은 키워드를 선택하는 light-weight unsupervised keyword extraction model이다. 훈련이 필요 없으며 도메인 의존적이지 않다는 특징이 있다.
주요 contribution point는 다음과 같다.
- Unsupervised method: 우리는 단일 문서에서 추출된 로컬 텍스트 통계적 특징을 기반으로 하는 light-weigth unsupervised keyword extraction model을 제안. 즉, 훈련 코퍼스가 필요 없음
- Corpus-independent: 우리는 외부 문서 집합 통계(IDF 등)에 의존하지 않고 단일 문서에서만 키워드를 추출할 수 있는 솔루션을 제공. 즉, 모든 텍스트에 적용할 수 있음
- Domain & language independent: YAKE!는 training corpus나 복잡한 외부 자원(ex WordNet, Wikipedia) 또는 언어 도구(ex NER, PoS 태거) 없이도 도메인과 언어를 지원. 단지 정적 정지어 목록만 필요
- Interior stopwords: YAKE!는 stop words(ex “game of Thrones”)가 포함된 키워드를 기존의 최신 방법들보다 높은 정확도로 추출
- Scale: YAKE!는 문서 길이에 비례하여 선형적으로 확장되며, 식별된 후보 용어의 수에 따라 조정
- Term-frequency free: 후보 키워드가 가져야 하는 최소 빈도나 문장 빈도에 대한 조건이 설정되지 않음. 따라서, 사용된 특징에 따라 키워드는 하나의 발생이나 여러 발생에 대해 중요하거나 중요하지 않을 수 있음
- Open Source: 마지막으로, 우리는 데모 [yake.inesctec.pt] [9]와 API [yake.inesctec.pt/api] 및 파이썬 패키지 [github.com/LIAAD/yake]를 제공
YAKE! algorithm
YAKE!는 다음 5개의 단계로 구성된다.

- text pre-processing and candidate term identification
- 기계가 읽을 수 있는 형식으로 전처리 후, 후보 키워드 생성 - feature extraction
- 후보 키워드들을 statistical feature로 표현 - computing term score
- feature를 이용해 용어의 importance를 반영하는 점수 생성 - n-gram generation and computing candidate keyword score
- 후보 키워드를 n-gram generation method를 이용해 생성 후 중요도에 따라 점수 부여 - data deduplication and ranking
- 유사한 키워드 중복 제거, 점수에 따라 정렬
1. Text pre-processing and candidate term identification
이 단계에서는 텍스트를 기계가 이해할 수 있도록 전처리 하는 과정이 포함된다.
- 텍스트가 주어지면 우선 문장으로 나눔(1행)
- 각 문장은 구분 기호가 있는 경우 chunk로 나누어지고 token으로 분리됨(3-5행)
- segtok 분리기의 web_tokenizer module 사용
- 각 토큰은 소문자로 변환되고 태그 구분 기호로 주석이 달림(7행)
- 불용어(stopword를 표시)
2. Feature extraction
feature extraction 단계에서는 먼저 statistic anlysis가 실행된다.
주요 statistic feature:
- token frequency(용어 빈도)
- offset sentences(용어가 발생하는 문장의 index)
- token frequency of acronyms(약어 빈도)
- token frequency of uppercase(대문자 용어 빈도)
그 후 위에서 계산한 statistic analysis를 기반으로 feature extraction 과정이 수행된다.
주요 feature:
- TCase(대소문자)
- 대문자 용어가 소문자 용어보다 relevant가 높음
- 모든 글자가 대문자인 약어도 고려
- 따라서 대문자로 발생하는 빈도가 높을수록 중요하게 간주됨
- TPosition(용어 위치)
- relevant가 높은 키워드는 문서 초반에 나타나는 경향이 있음. 문서 중간이나 끝에 발생하는 단어는 덜 중요
- 이전에 시도된 적 없는 접근임
- TFNorm(용어 빈도 정규화)
- 항상 빈도수가 높을수록 중요한 용어는 아님
- 이를 보정할 수 있도록 MeanTF(평균 빈도)+deviation 으로 나누어줌
- TRel(문맥과의 용어 관련성)
- 후보 용어의 양쪽에 함께 등장하는 서로 다른 용어의 수가 많을수록 t의 중요성이 떨어진다고 주장
- 즉 불용어처럼 쓰이는 것일 수도 있음
- TSentence(다른 문장에서의 용어)
- 후보가 다른 문장에 얼마나 자주 등장하는지 정량화
- 이러한 용어가 더 중요한 용어일 가능성이 높다는 가정을 반영
각 feature의 정확한 feature score 계산 수식은 논문에 자세히 나와있다. 궁금하면 참고하자.
3. Computing term score
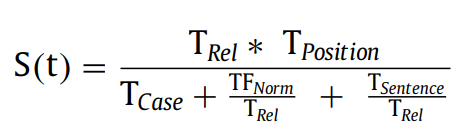
위에서 계산한 feature를 이용해 term score를 다음과 같이 계산할 수 있다.
- TFNorm과 TSentence가 TRel로 나누어지는 것을 알 수 있음. 이는 자주 등장하고 여러 문장에서 나타나는 용어에 높은 가치를 부여하기 위함. 해당 용어가 중요할 가능성을 나타내는 것임
- 실제로 일부 용어는 여러 번 등장하고 많은 문장에서 등장할 수 있지만 쓸모없을 수 있음. 이런 애들은 페널티를 받아야 함.
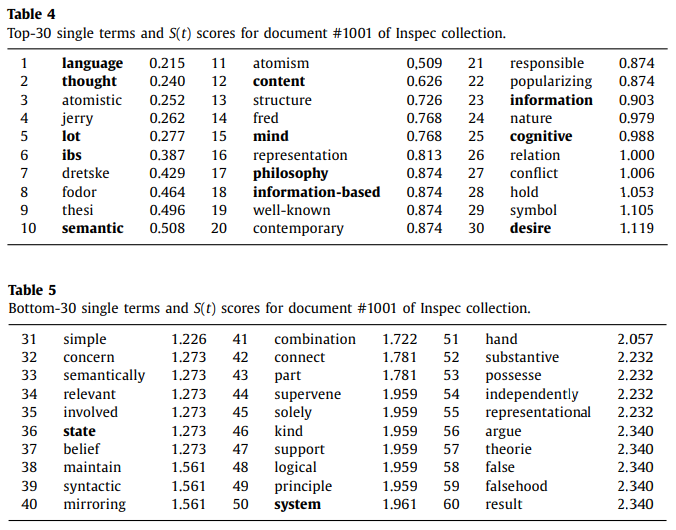
위의 S(t) 점수를 이용해 ranking을 매긴 결과이다. 굵은 글씨는 해당 source의 keyword에 해당된다.
4. n-gram generation and computing candidate keyword score
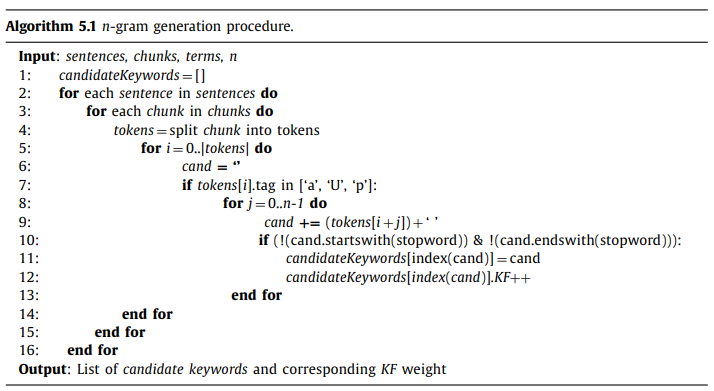
- 한 단어씩 나누는게 1-gram이라면 n-gram은 단어를 n개씩 묶어 sliding window를 통해 처리하는 것이다. 단, 다른 chunk 내의 용어 끼리는 묶지 않는다. 이는 관련없는 용어들의 묶음 생성을 방지하기 위해서이다.
- 또한 stopword로 시작하는 용어는 keyword일 확률이 2.3%밖에 되지 않으므로 이런 키워드는 후보로 고려하지 않는다.
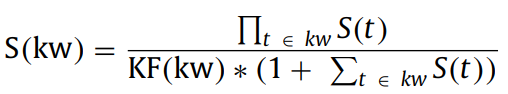
- 이제 다음과 같은 score function을 통해 score를 계산한다. kw는 하나 이상의 용어로 구성된 후보 키워드이다. S(KW)는 최종 점수이다.
- 후보 키워드의 점수는 여러 용어로 구성된 후보 키워드의 S(t)점수를 곱하여 결정된다.
- 그러나 이 곱의 문제는 후보 키워드의 길이가 길수록 유리할 수 있다는 것이다. 이를 줄이기 위해 S(t)의 합 +1과 후보 키워드 빈도KF로 나누어준다.
5. Data deduplication and ranking
이 과정에서는 유사성이 높은 token을 제거하는 역할을 한다.
각 후보들의 유사성을 계산한 뒤 threshold 이상이면 제거한다. 가장 점수가 좋은(낮은) 것만 남기고 제거한다.
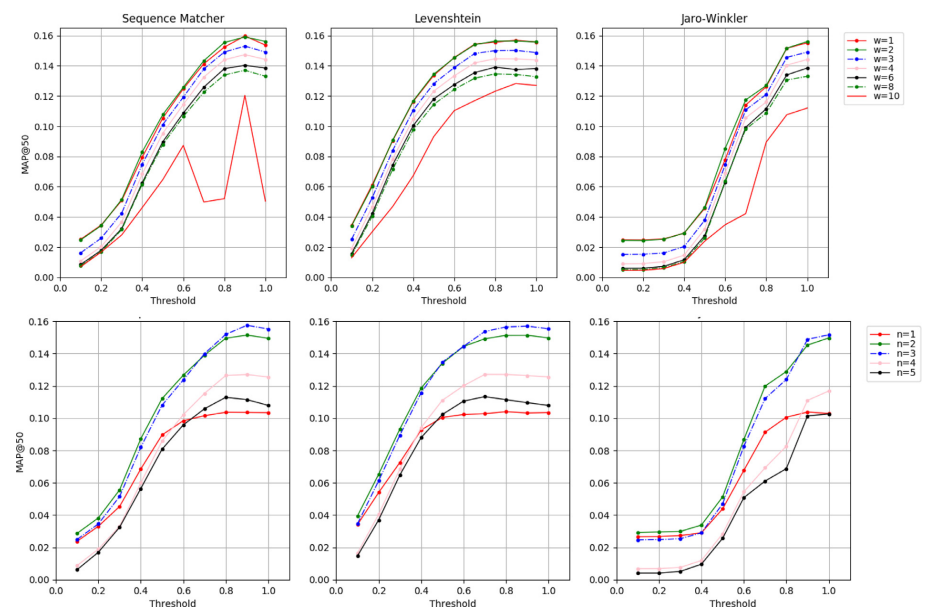
3가지의 유사성 측정 방법을 사용한다.
- Levenshtein similarity
- Jaro-Winkler similarity
- sequence matcher
Experiments