이번 글에서는 DeepLab V3+ Xception의 BackBone이 되는 Xception과 Xception의 이전 버전 모델인 Inception에 대해 소개한다.
Inception

Inception은 2014년 IRSVRC에서 1등한 모델로 GoogLeNet이라고도 부른다. Inception은 노드 간의 연결을 줄이면서(Sparse Connectivity), 행렬연산은 Dense하도록 처리한다. Inception의 기본 가정은 채널과 공간의 convolution을 분리하는 것이다.
위의 그림을 보면 모두 1 * 1 conv를 진행한 후 각자 다른 conv를 이용해 convolution을 수행하고 결과를 concatenation한다. 이 과정으로 채널과 공간의 convolution을 분리하게 된다.
Xception

Xception은 eXtreme Inception이라고도 부르며 말 그대로 Inception을 Extreme하게 해보자는 뜻이다. 위의 그림과 같이 1 1 * 1 conv를 이용하여 output channels를 생성하고 각각에 대해 spatial convolution을 수행하는 것이다. 즉 Depthwise separable Convolution와 비슷한 원리로 depthwise(spatial)와 pointwise convolution(channel dimension)을 나누어 연산량을 줄임과 동시에 성능을 향상시킬 수 있다.
Xception은 무엇이 달라졌을까?
- Depth-wise Separable Convolution은 먼저 Depth-wise, 이후 point-wise(1 * 1 kernel)을 진행했는데 Xception은 순서를 바꾸어 진행한다.
- Inception 모델의 경우 첫 연산 후 ReLU(Non-linearity)를 적용하지만 Xception은 적용하지 않는다.
- Residual - connection을 적용한다.
Xception 전체 구조
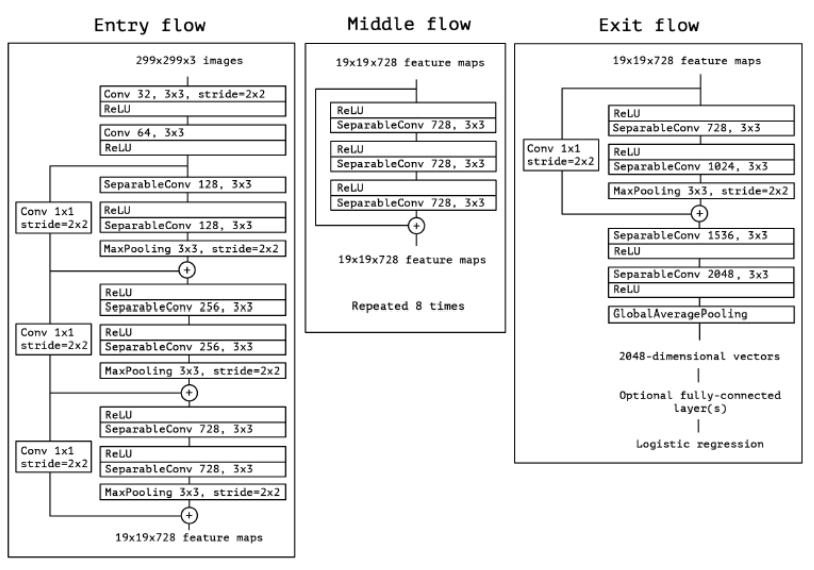
Xception 모델은 3개의 구조로 나뉜다.
1. Entry flow
- 299 * 299 * 3의 image를 이용한다.
- 모든 convolution 이후 batch normalization을 사용한다.
- Residual Connection으로 연결된 Xception 모듈을 3번 사용하여 19 * 19 * 728의 feature map을 생성한다.
2. Middle flow
- Residual Connection으로 연결된 Xception 모듈을 8번 반복한다. feature map의 크기변화는 없다.
3. Exit flow
- Global Average Pooling -> Fully-connected layer -> Logistic Regression 을 통해 output을 산출한다.
'Computer Vision > Semantic Segmentation' 카테고리의 다른 글
| DeepLab V3+ Xception (0) | 2022.08.01 |
|---|---|
| Depth-wise Separable Convolution (for DeepLab V3+ Xception) (0) | 2022.08.01 |
| DeepLab V3+ (0) | 2022.08.01 |
| Atrous Convolution, Atrous Spatial Pyramid Pooling(ASPP) (for DeepLab V3+) (0) | 2022.08.01 |
| Segmentation Metric(Pixel Accuracy, Intersection over Union) (0) | 2022.08.01 |